Table of Contents
History of AWS Glue
AWS Glue was initially released on August 14, 2017. When initially released, AWS Glue offered alpha and/or beta releases versioned 0._ with Glue 0.9 still available for new and old jobs at the time of writing this post. AWS Glue 2.0 was announced in August 2020 along with a bunch of improvements including reduced job startup times (with 10x reduction) and 1-minute minimum billing duration (with 1-second increments). That means Glue 2.0 enabled micro-batch and time-sensitive workloads with cost-effective billing.
AWS Glue 3.0 was announced on August 19, 2021. In the last four years, AWS Glue has come a long way in terms of its offerings as a ETL-as-a-Service (ETLaaS). According to AWS Big Data Blog, “In the last year, AWS Glue has evolved from an ETL service to a serverless data integration service, offering all the required capabilities needed to build, operate and scale a modern data platform.”
AWS Glue 3.0
AWS Glue 3.0 offers Apache Spark 3.1 for batch and streaming data workloads. Apache Spark 3.1 runtime in AWS Glue 3.0 includes enhanced optimizations from AWS Glue and AWS EMR teams. These optimizations support faster data integration and processing including in-memory processing of columnar data formats, enhanced shuffles, and adaptive query execution in Spark. AWS Glue 3.0 also comes with newer JDBC drivers supporting all native sources like MySQL, PostgreSQL, SQL Server, Oracle and MongoDB.
AWS Glue 3.0 speeds up performance by as much as 2.4 times compared to AWS Glue 2.0 with the use of vectorized readers, which are implemented in C++. It also uses micro-parallel SIMD CPU instructions for faster data parsing, tokenization and indexing. Additionally, it reads data into in-memory columnar formats based on Apache Arrow for improved memory bandwidth utilization and direct conversion to columnar storage format such as Apache Parquet. – AWS Big Data Blog
AWS Glue 3.0 brings a lot of features, among which, these are the features that got me to upgrade my Glue jobs to Glue 3.0:
- Apache Spark has an upgraded, performance-optimized runtime: An enhanced runtime based on Apache Spark 3.1.1 is available with Glue 3.0, which brings a host of new and improved features over Apache Spark 2.4.3 in Glue 2.0. The list includes a new framework for adaptive query execution, improved dynamic partition pruning, an enhanced query compiler, etc.
- Auto Scaling in Glue 3.0 improves efficiency and reliability: Glue 2.0 supports configuring the number of workers for Spark jobs for parallel processing. However, it can be hard to configure the right number of workers without doing many trials; and even then, it may change depending on the workload. Glue 3.0 with Auto Scaling helps here, and also, jobs perform better.
- Amazon S3 offers faster read and write access with Glue 3.0: AWS Glue 3.0’s enhanced runtime uses vectorized readers with Dynamic Frames and optimized output committers for Amazon S3. These help boost read and write speeds using S3.
- Fine-grained access control to data and ACID transactions: AWS Glue 3.0 brings better support for Lake Formation including fine-grained access control while reading data and ACID transactions while writing data in Spark jobs. Glue 3.0 with Lake Formation allows access control at database, table, column, row, and cell-level via resource names and tag attributes.
Glue 3.0 vs. Glue 2.0
Firstly, a performance benchmark conduced by the AWS Glue team (see the graph below) shows that Glue 3.0 performed as much as 70% better than Glue 2.0 while converting large schemaful datasets from row-based CSV format to columnar-based Apache Parquet format. It performed 150% better than Glue 2.0 for converting schemaless datasets from CSV format to Apache Parquet format.
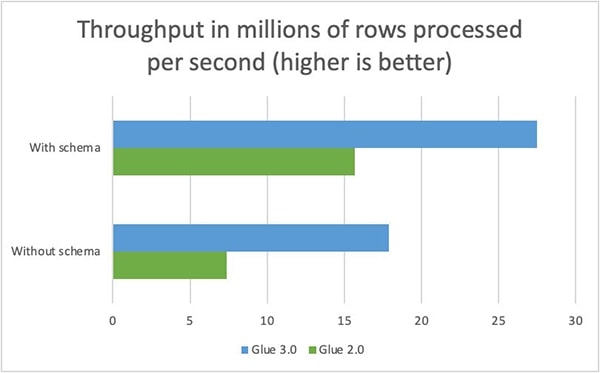
Second, let’s compare the architecture, features and job options of Glue 2.0 and Glue 3.0, which will help you decide if you can and want to upgrade your Glue 2.0 jobs to Glue 3.0. At the minimum, your jobs will benefit from the better performance of Glue 3.0.
| Feature | Glue 2.0 | Glue 3.0 |
|---|---|---|
| Apache Spark | Spark 2.4.3 (open-source version) | Spark 3.1.1 (optimized version from AWS Glue and EMR teams) |
| Auto Scaling | Not supported | Supported |
| AWS Glue Spark shuffle manager with Amazon S3 | Supported | Not supported (yet) |
| Python 2.x | Python 2.7 | Not supported |
| Python 3.x | Up to Python 3.7 | Python 3.7 or above |
| Scala | Scala 2.11 | Scala 2.12 |
| Startup time | Slower than Glue 3.0 | Faster than Glue 2.0 |
There are more dependency upgrades including JDBC drivers and Python modules. Check the complete list on AWS’s pages:
Conclusion
AWS Glue 3.0 offers a ton of improved features, which will interest anyone to switch to Glue 3.0. My favorite features are the improved runtime of Apache Spark and Auto Scaling support in Glue 3.0. The reason being these two features combinedly provide a boost in performance for a Glue 3.0, Spark-based job compared to the same job running using Glue 2.0. What do you think about it?
If you’re interested in trying out Glue 3.0, check out Migrating AWS Glue jobs to AWS Glue version 3.0 (AWS Glue Developer Guide) . Also, Glue 2.0 is reaching end of support on March 31, 2023; so nevertheless, you will want to upgrade your Glue jobs to Glue 3.0.
References
- Documentation history for AWS Glue [ AWS Glue Developer Guide (original) (archived) ]
- AWS Glue version 2.0 featuring 10x faster job start times and 1-minute minimum billing duration [ AWS News Blog (original) (archived) ]
- Introducing AWS Glue 3.0 with optimized Apache Spark 3.1 runtime for faster data integration [ AWS Big Data Blog (original) (archived) ]
- Migrating AWS Glue jobs to AWS Glue version 3.0 [ AWS Glue Developer Guide (original) (archived) ]
- AWS Glue version support policy [ AWS Glue Developer Guide (original) (archived) ]
- Dependency upgrades [ AWS Glue Developer Guide (original) (archived) ]
- JDBC driver upgrades [ AWS Glue Developer Guide (original) (archived) ]
- Using Python libraries with AWS Glue [ AWS Glue Developer Guide (original) (archived) ]